Data Product
Retail Data Pipeline
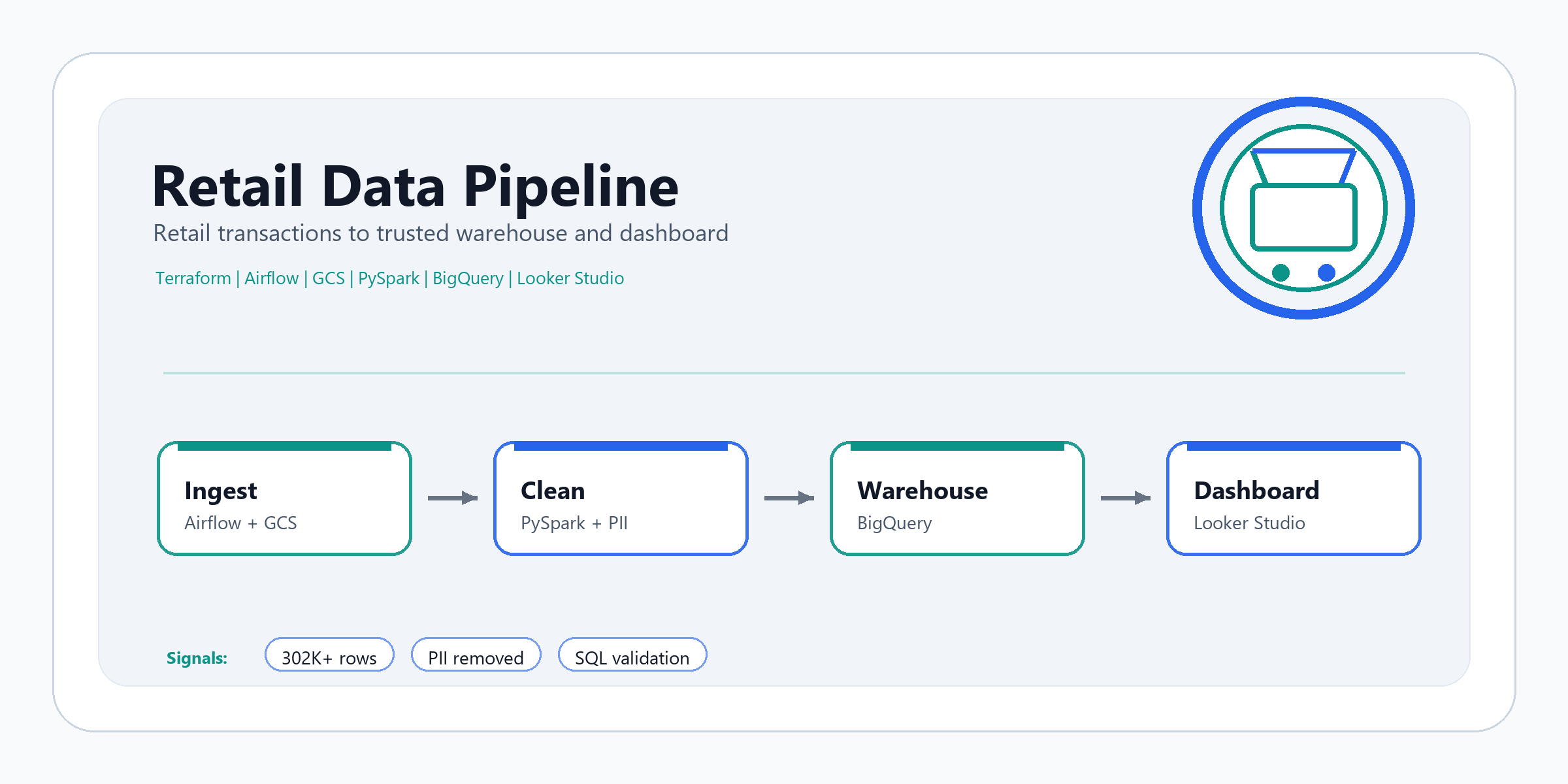
Cloud-based retail analytics workflow that moves raw transaction data through storage, orchestration, transformation, validation, warehouse delivery, and business reporting.
Overview
Retail Data Pipeline is a cloud-native technical project for transaction analytics. It moves retail data from local CSV ingestion into cloud storage, warehouse tables, transformation logic, validation queries, and a dashboard.
The project demonstrates the full lifecycle of an analytics-ready system: infrastructure provisioning, raw ingestion, warehouse loading, cleaning, privacy-aware transformation, data quality validation, and reporting delivery.
Problem
Retail datasets combine product, customer, payment, location, time, and revenue information. A useful technical workflow must preserve raw traceability while producing trusted, clean, business-ready outputs.
Solution
Terraform provisions the GCP foundation, Docker Compose runs local Airflow, and Airflow moves raw and cleaned data between local storage, GCS, and BigQuery. PySpark applies type casting, duplicate removal, null handling, invalid-value filtering, category normalization, and privacy-aware removal of sensitive fields.
The clean output is loaded into BigQuery and validated through SQL checks before being presented through Looker Studio.
Technical Highlights
- Terraform-managed GCS, BigQuery datasets, and Dataproc foundation.
- Airflow DAGs for raw upload, warehouse load, clean upload, and transformed load.
- PySpark transformation workflow for analytical cleaning and schema control.
- SQL validation for nulls, duplicate transactions, future dates, negative purchases, and payment categories.
- Dashboard layer for retail sales, product, customer, and geographic analysis.
Architecture
The workflow follows a clear raw-to-reporting path:
- Provision cloud infrastructure.
- Upload raw CSV data to GCS.
- Load raw data into BigQuery with an explicit schema.
- Transform with PySpark.
- Upload clean output to GCS.
- Load clean data into BigQuery.
- Run validation queries.
- Publish BI reporting through Looker Studio.
Future Improvements
- Convert notebook transformation into a reusable PySpark job.
- Add automated Airflow dependencies for a single end-to-end run.
- Add Great Expectations or dbt tests for structured data quality.
- Add CI checks for DAG imports and Terraform formatting.